はじめに
AWS VPC内のネットワークフロー情報を保存する仕組みとしてVPC Flow Logsというものがあります。
VPC フローログは、VPC のネットワークインターフェイスとの間で行き来する IP トラフィックに関する情報をキャプチャできるようにする機能です。フローログデータは Amazon CloudWatch Logs と Amazon S3 に発行できます。フローログを作成すると、選択した送信先でそのデータを取得して表示できます。
出典:https://docs.aws.amazon.com/ja_jp/vpc/latest/userguide/flow-logs.html
VPC Flow Logsは2015年頃にGAされた機能のようです。最近ではログ保存タイミングを1分間隔まで縮めることができるようになり再び注目を集めています。
今回は、そんなVPC Flow LogsをAmazon Athenaで読み込んで、SQLクエリを使った解析を行ってみようと思います。
用意するもの
- PC
- ブラウザ
- AWSアカウント
検証環境構築
以下のステップで検証環境の構築を行います。
S3バケット作成
S3の管理コンソール画面からバケットを作成するという青いボタンを押下します。
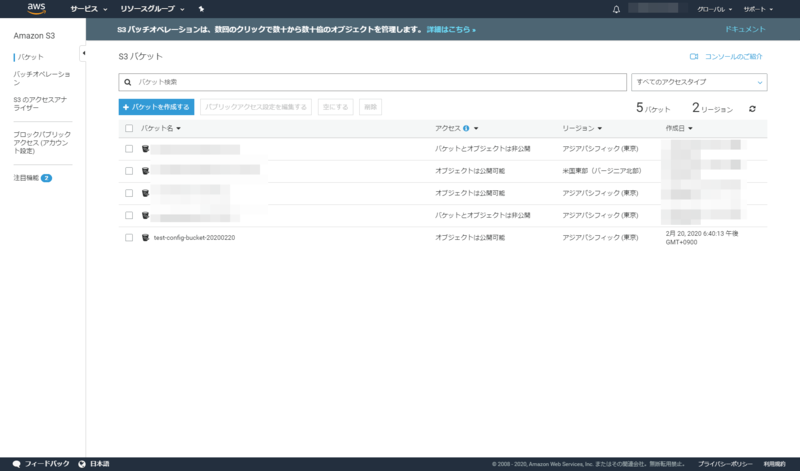
任意の名前をつけます。ここでは以下のパラメーターを入力しました。
入力したら作成ボタンを押下します。
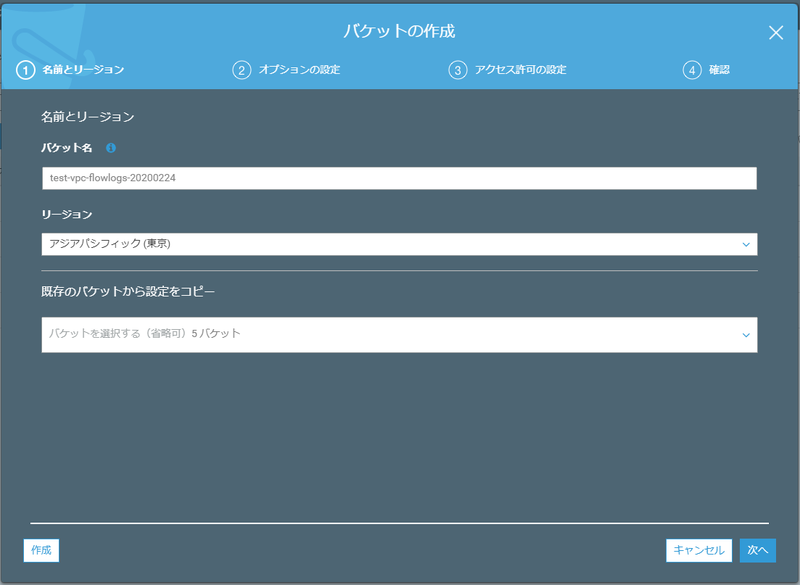
S3バケットが作成されたことを確認します。
ここでバケットARNをコピーするを押下してバケットARNをクリップボードにコピーしておきましょう。
VPC FlowLogsの有効化
VPCダッシュボードに移動して、VPC FlowLogsを有効にしたいVPCを選択します。
下ペインのフローログタブを選択し、フローログの作成という青いボタンを押下します。

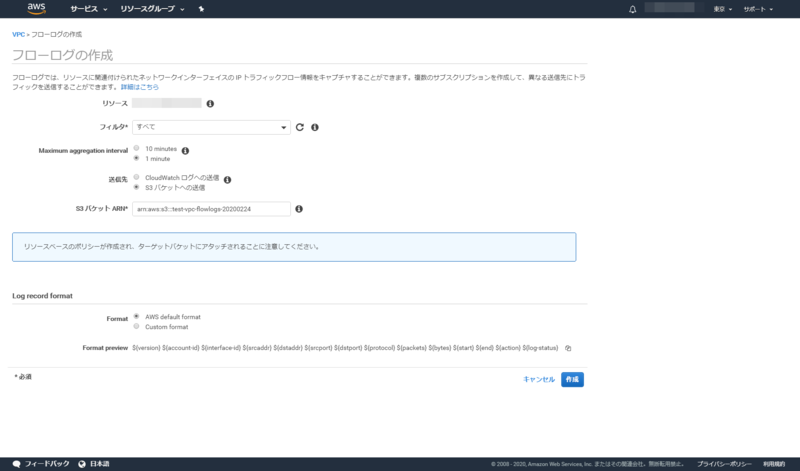
フローログの設定を行います。
- リソース:対象のVPCであることを確認しましょう。
- フィルタ:許可/拒否/すべての3種類から選べます。今回は
すべてを選択しました。 - Mximum aggregation interval:ログ取得間隔時間を指定します。今回は
1 minuteとしました。 - 送信先:今回は
S3バケットへの送信を選択します。 - S3バケットARN:S3の作成で作ったS3バケットのARNを入力します。
- Log record format:AWS default formatを選択します。
Custom formatにするとログフォーマットを自分好みに変えることができます。
パラメーターの入力が終わったら作成ボタンを押下します。
次のフローログが作成されました。と表示されれば成功です。
VPCダッシュボードに戻ると下ペインのフローログタブにフローログが作成されています。
しばらくおいてからS3バケットを見ると、フローログが作成されています。
フォルダ階層は{バケット名}/AWSLogs/{アカウント番号}/vpcflowlogs/ap-northeast-1/{年(西暦)}/{月}/{日}となります。
Athenaの設定
つづいて、取得したVPC FlowLogsに対してSQLクエリを発行できるよう、Athenaの設定をします。
ちなみに、AthenaはAWSマネージドのクエリエンジンです。
https://aws.amazon.com/jp/athena/
Amazon Athena はインタラクティブなクエリサービスで、Amazon S3 内のデータを標準 SQL を使用して簡単に分析できます。Athena はサーバーレスなので、インフラストラクチャの管理は不要です。実行したクエリに対してのみ料金が発生します。
サービスからAthenaを選択し、Get Startedという青いボタンを押下します。
データベースの作成
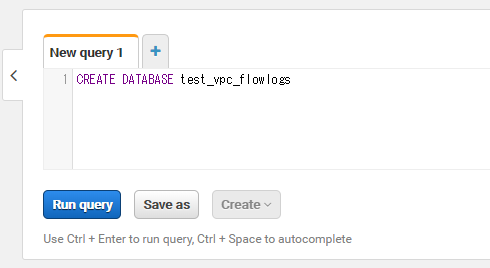
右ペインのNew query 1タブにクエリを入力し、データベースを作成します。データベース名は任意です。
CREATE DATABASE test_vpc_flowlogs
クエリを入力したら、Run queryという青いボタンを押下します。
テーブルの作成
左ペインのプルダウンメニューから先程作成したデータベース(test_vpc_flowlogs)を選択し、New query 1タブ(+ボタンから違うタブを生成してもOK)にクエリを入力します。
{AWS ID}にはご自身のAWSアカウントIDを入力してください。
CREATE EXTERNAL TABLE IF NOT EXISTS test_vpc_flowlogs.test_table_vpc_flowlogs ( version int, account string, interfaceid string, sourceaddress string, destinationaddress string, sourceport int, destinationport int, protocol int, numpackets int, numbytes bigint, starttime int, endtime int, action string, logstatus string ) PARTITIONED BY (dt string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' LOCATION 's3://test-vpc-flowlogs-20200224/AWSLogs/{AWS ID}/vpcflowlogs/ap-northeast-1/' TBLPROPERTIES ("skip.header.line.count"="1");
クエリを入力したら、Run queryという青いボタンを押下します。
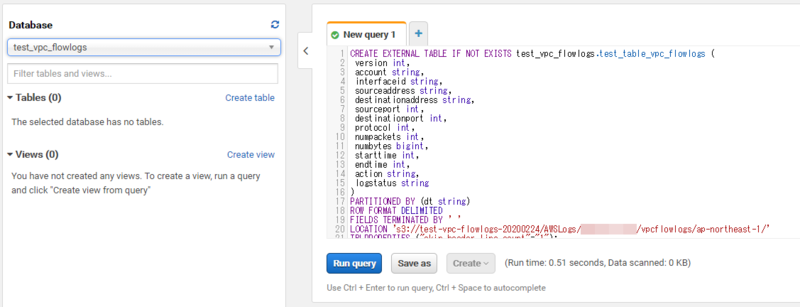
Result画面にQuery successfulと表示されれば成功です。

SQLクエリの発行
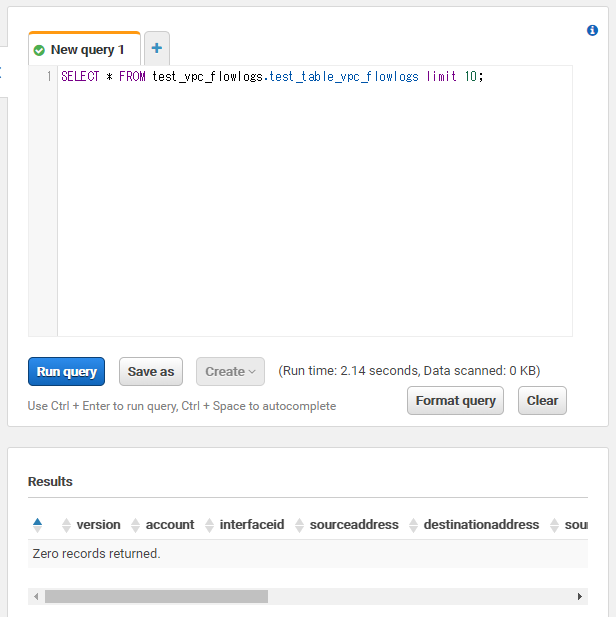
この状態でSELECTクエリを発行してみます。
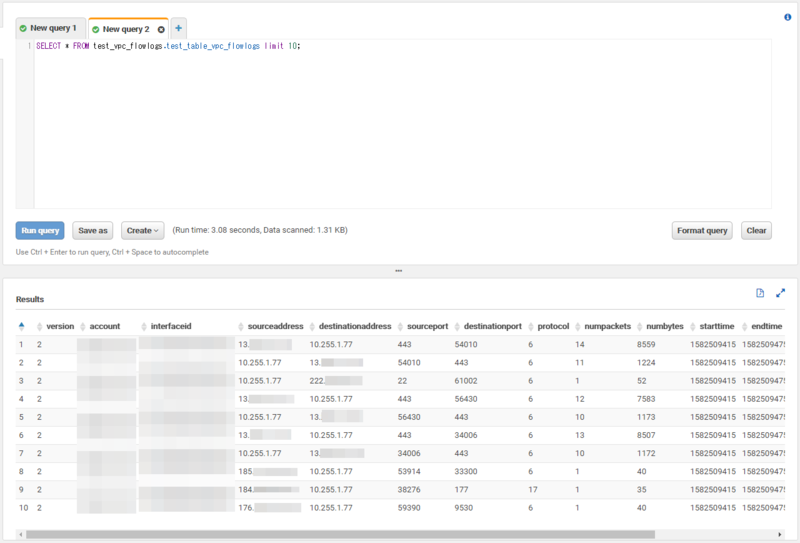
SELECT * FROM test_vpc_flowlogs.test_table_vpc_flowlogs limit 10;
するとZero records returned.と結果が表示されました。これはパーティションが適切ではないために示されます。パーティションは、クエリでスキャンするデータ量を制限するために有効です。
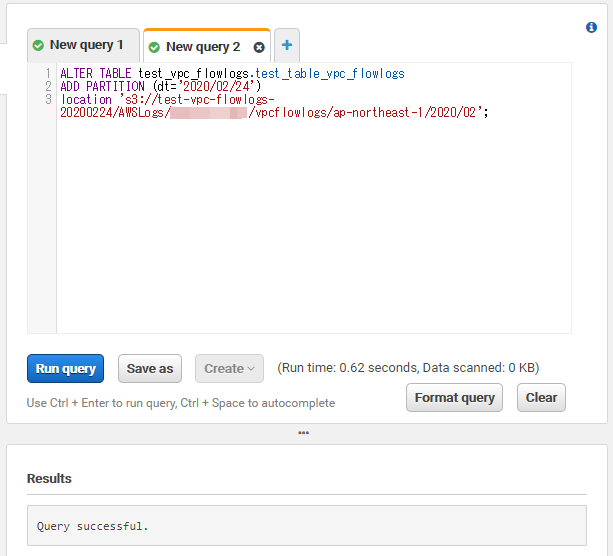
パーティション設定を変更するにはALTER TABLEクエリを発行します。
{AWS ID}にはご自身のAWSアカウントIDを、日付も任意の値を入力してください。
ALTER TABLE test_vpc_flowlogs.test_table_vpc_flowlogs ADD PARTITION (dt='2020/02/24') location 's3://test-vpc-flowlogs-20200224/AWSLogs/{AWS ID}/vpcflowlogs/ap-northeast-1/2020/02';
Query successfulとResultに表示されれば成功です。
この状態でもう一度SELECTクエリを発行してみます。
SELECT * FROM test_vpc_flowlogs.test_table_vpc_flowlogs limit 10;
すると、今度はデータを表示することができました。
ユースケース
ユースケースに沿っていくつかSQLクエリを発行してみたいと思います。データベースは素人なので変なクエリ打ってるかもしれません。あくまで参考まで。
ログ数をカウントしたい
count()関数を使います。
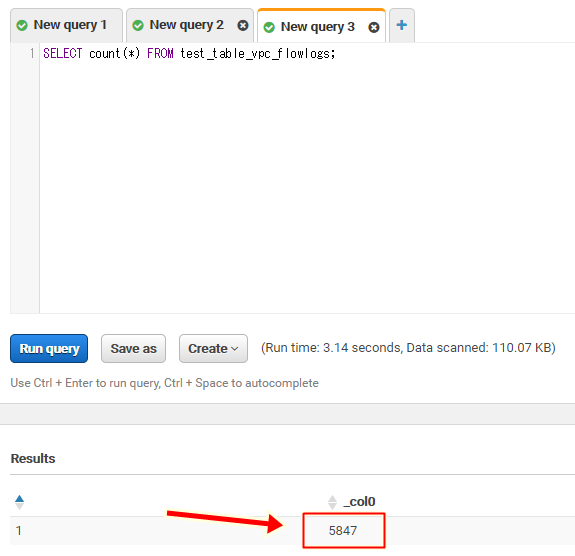
SELECT count(*) FROM test_table_vpc_flowlogs;
5847行のログがあるようです。
Denyされている通信を可視化したい
WHERE句でaction列がREJECTであるものを指定します。
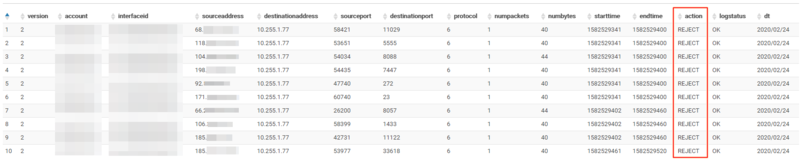
SELECT * FROM test_table_vpc_flowlogs WHERE action = 'REJECT' LIMIT 10;
REJECTのログだけ抽出することができました。
逆にPermitされたものを指定したい場合はACCEPTを指定すればOKです。
特定のNICの通信を可視化したい
以下のようなSQL文を発行します。
SELECT DISTINCT interfaceid, protocol, sourceaddress, sourceport, destinationaddress, destinationport FROM test_table_vpc_flowlogs WHERE interfaceid = 'eni-xxxxxxxxxxxxxxxxx' AND action = 'ACCEPT' ORDER BY sourceaddress, sourceport, destinationaddress, destinationport;
たとえばポート番号の10000未満だけ表示したければWHERE句で<演算子を使います。
SELECT DISTINCT interfaceid, protocol, sourceaddress, sourceport, destinationaddress, destinationport FROM test_table_vpc_flowlogs WHERE interfaceid = 'eni-xxxxxxxxxxxxxxxxx' AND action = 'ACCEPT' AND sourceport < 10000 AND destinationport < 10000 ORDER BY sourceaddress, sourceport, destinationaddress, destinationport;
エフェメラルポート(一時ポート)を排除したい場合はNOT BETWEENを使って排除します。
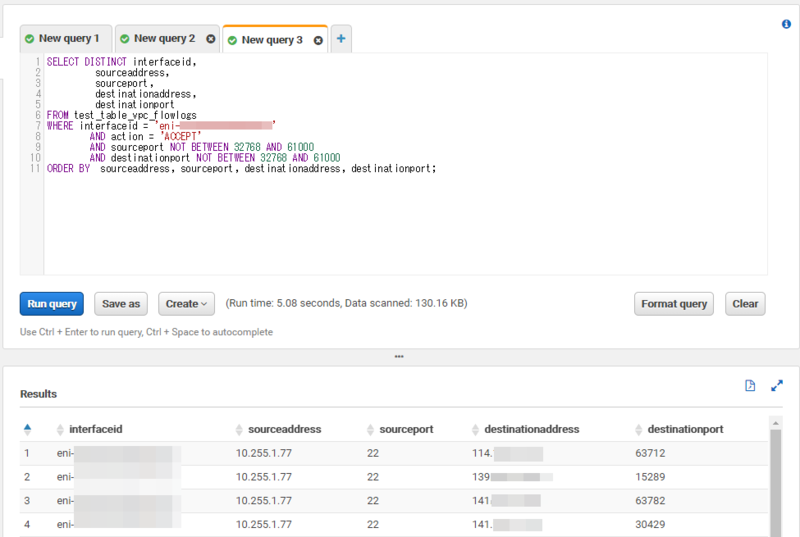
SELECT DISTINCT interfaceid, protocol, sourceaddress, sourceport, destinationaddress, destinationport FROM test_table_vpc_flowlogs WHERE interfaceid = 'eni-xxxxxxxxxxxxxxxxx' AND action = 'ACCEPT' AND sourceport NOT BETWEEN 32768 AND 61000 AND destinationport NOT BETWEEN 32768 AND 61000 ORDER BY sourceaddress, sourceport, destinationaddress, destinationport;
エフェメラルポートは以下表を参照してください。
| 種別 | FROM | TO |
|---|---|---|
| RFC 6056 | 1024 | 65535 |
| IANA | 49152 | 65535 |
| FreeBSD | 49152 | 65535 |
| Linuxカーネル | 32768 | 61000 |
| Windows XP | 1025 | 5000 |
| Windows Server 2003 | 1025 | 5000 |
| Windows Vista以降 | 49152 | 65535 |
| Windows Server 2008以降 | 49152 | 65535 |
こんな感じで結果が返ってきます。
豆知識
知っておくと便利な情報を書いておきます。
結果を保存する
クエリを発行した結果はCSVでダウンロードできます。SQLに慣れていない場合は、ある程度の情報だけ抽出してCSVをダウンロード、エクセルでゴリゴリみたいなこともできますね。
ショートカットキー
Run queryはCtrl + Enterでも実行できます。
料金
最後に料金について。
半日遊びましたが、こんなもんです。

Athenaはコストパフォーマンスに大変すぐれています。個人で検証する分にはほぼお金がかからないと言えるでしょう。
スキャンされたデータ 1 TB あたり 5.00USD
参考:https://aws.amazon.com/jp/athena/pricing/
インフラを何も用意する必要がないのに気軽にSQLを触れる環境は本当に楽ちんだな~と思いました。
以上